
Java语言中的Switch-case语句有两种实现方法,如果case值能够编码成一个索引表,则实现成tableswitch指令,否则实现为lookupswitch指令。
如何理解能编码成一个索引表?我的理解是case的值比较集中的话,就可以编码成一个索引表。
如下面的Switch-case语句
1 | switch (N){ |
编译后,查看Class文件,编译器自动帮我们补全了1~14之间的其他没有写出来的case4,9,10,12
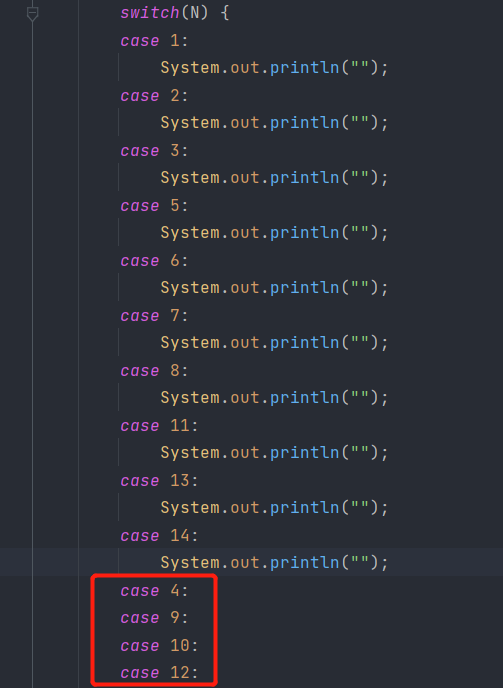
我们利用Jclasslib查看底层用的是哪条指令
1 | 3 tableswitch 1 to 14 |
发现底层字节码指令使用的是tableswitch指令
tableswitch指令的底层数据结构类似于
1 | type TABLE_SWITCH struct { |
对于我们上面的case,这里的high为14,low为1,表中一共有hight-low+1个分支项,当jvm遇到tableswitch指令的时候,首先会从操作数栈中弹出一个int变量,然后看它是否在low和high给定的范围之内,如果在,则从jumpOffsets表中查出偏移量进行跳转,如果不是,则按照defaultOffset跳转,可以看到,tableswitch的执行效率是比较高的,只要拿到了switch(key),直接返回jumpOffsets[index-self.low]就知道了要跳转的偏移量是多少了。
那么如果case比较分散的话,是什么情况呢?我们测试下面的这个switch-case语句
1 | switch(K) { |
同样先查看class文件
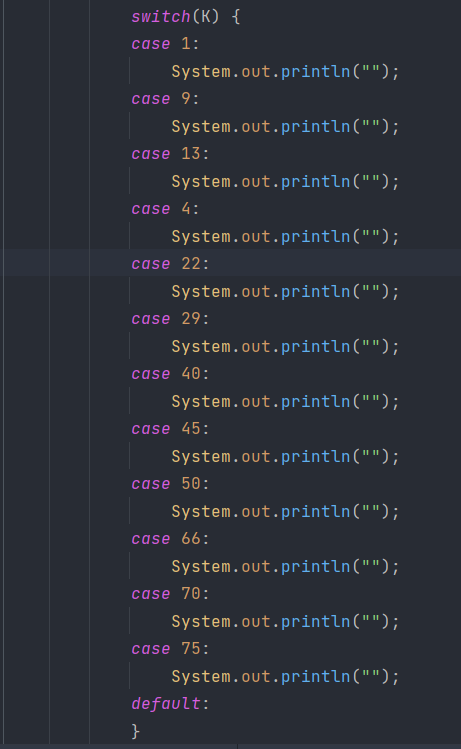
发现这里并没有像之前那样,补充1~75之间缺少的case了。
继续用JclassLib查看字节码指令
1 | 155 lookupswitch 12 |
发现底层的字节码指令使用过的是lookupSwitch了
lookupSwitch的底层实现类似于
1 | type LOOKUP_SWITCH struct { |
为什么Java虚拟机的设计者要采用两条不同的指令去实现switch-case语句呢,就是因为switch-case的case会出现集中和稀疏两种的情况
-
当case出现的比较集中,我们使用tableSwitch语句,通过牺牲少量的空间(因为有一些无效的映射,如前面的case4,9,10,12)都是无效的映射,来换取更高的效率。将switch-case实现为tableSwitch语句,在判断的时候,只需要判断case是否在low和high之间,如果在,之间返回jumpOffsets[index-self.low]拿到对应的跳转偏移量,不在的话就返回defaultOffset。
-
而case出现的比较稀疏,此时我们仍然使用tableSwitch的话,牺牲的空间就太多了,无效的映射占用的空间甚至比有效的映射占用的空间还多,所以我们选择牺牲一些时间,来节省空间。通过实现为lookupswitch指令。lookupswitch底层其实就是精确的映射了,官方也称为pairs,(case,offset)对,java虚拟机规范还规定了
The match-offset pairs are sorted to support lookup routines that are quicker than linear search.
对匹配偏移量对进行排序以支持比线性搜索更快的查找例程。
也就是可以通过对case进行排序,然后根据传入进来的值选择对应case的时候就可以使用二分查找以获得比线性搜索更快的查找速度。
只有什么样的case算集中,什么样的case算稀疏,要实现为tableswitch还是lookupSwitch,可以就需要编译器在空间和时间的考虑上做思考了,如果追求更高的速率,那么可以放宽集中的要求,多实现tableswitch,如果追求空间的节省,那么可以收紧集中的要求,多实现为lookupSwitch。
又是一个时间和空间博弈的问题…
溜…