
CANS3-CLASSICAL ENCRYPTION TECHNIQUES(传统加密技术)
1 SYMMETRIC CIPHER MODEL
1.1 五个基本成分
对于一个对称加密的过程,有五个基本成分:
- 明文 Plaintext 原始的可理解的消息或数据,是加密算法的输入
- 加密算法 Encryption algorithm 加密算法是对明文进行各种代替(substitutions)和置换(transformation),以产生不可理解的密文
- 密钥 Secret key 密钥也是加密算法的输入,独立于明文和算法,算法根据所用的特定密钥而产生不同的输出,算法所进行的各种代替和置换也依靠密钥。
- 密文 Ciphertext 密文是加密算法的输出,直观看起来不可理解其代表的意识,依赖于明文和密钥,对于给定的相同的明文,不同的密钥将产生不同的密文。
- 解密算法 Decryption algorithm 本质上是加密算法的逆运算,输入为密文和密钥,输出原始明文
而对称密码对称的意思就是加密使用的密钥和解密使用的密钥是相同的。
1.2 对称加密简化模型
图3.1是对称加密的简化模型:
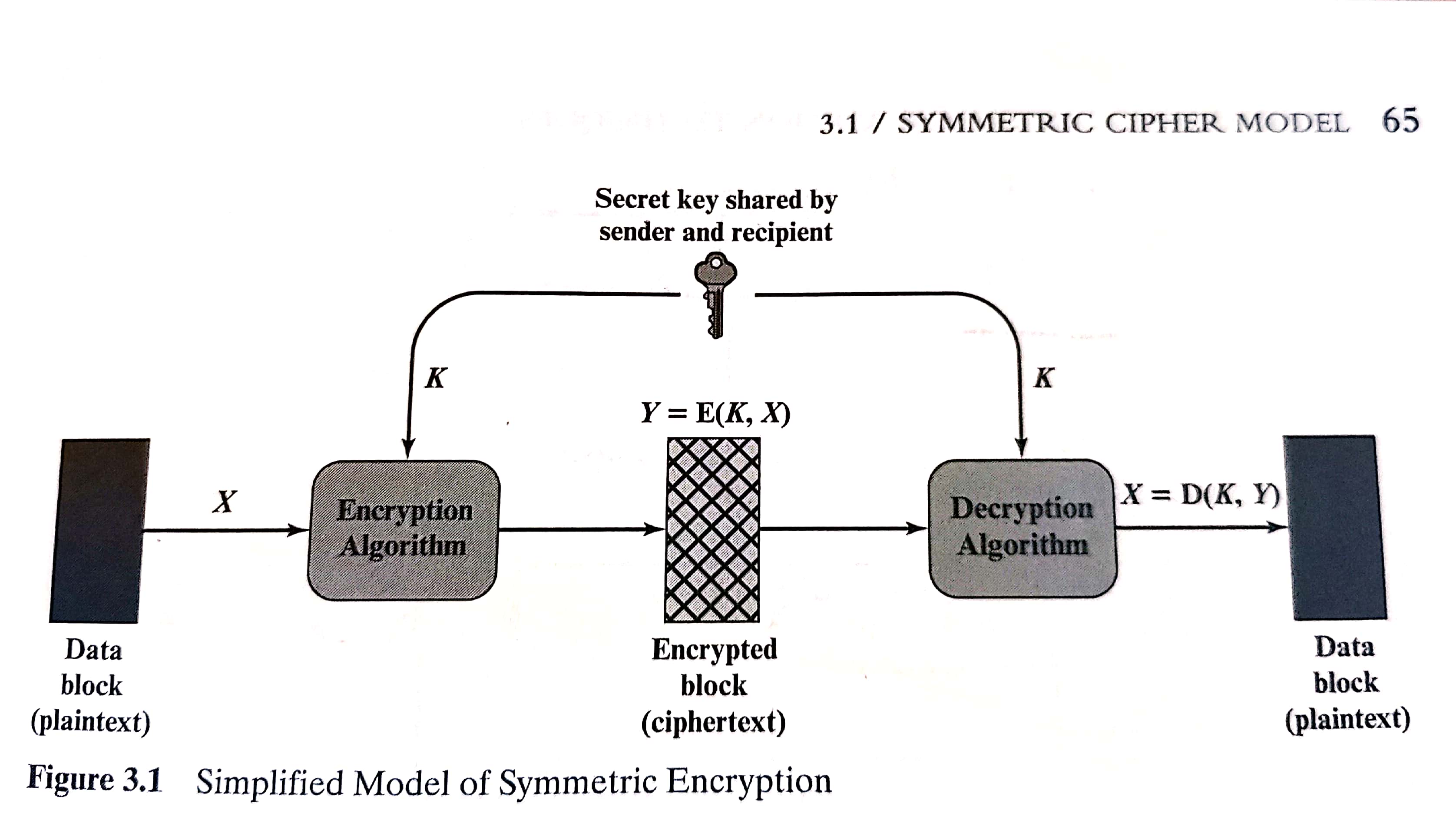
在一般的情况下,我们假设已知密文和加密/解密算法而破译消息是不实际的(impratical),换而言之,我们并不需要对加密解密算法保密,最重要的是对密钥保密。使用对称密码,首要的安全问题就是密钥的保密性。
从图3.2理解对称加密的基本过程:
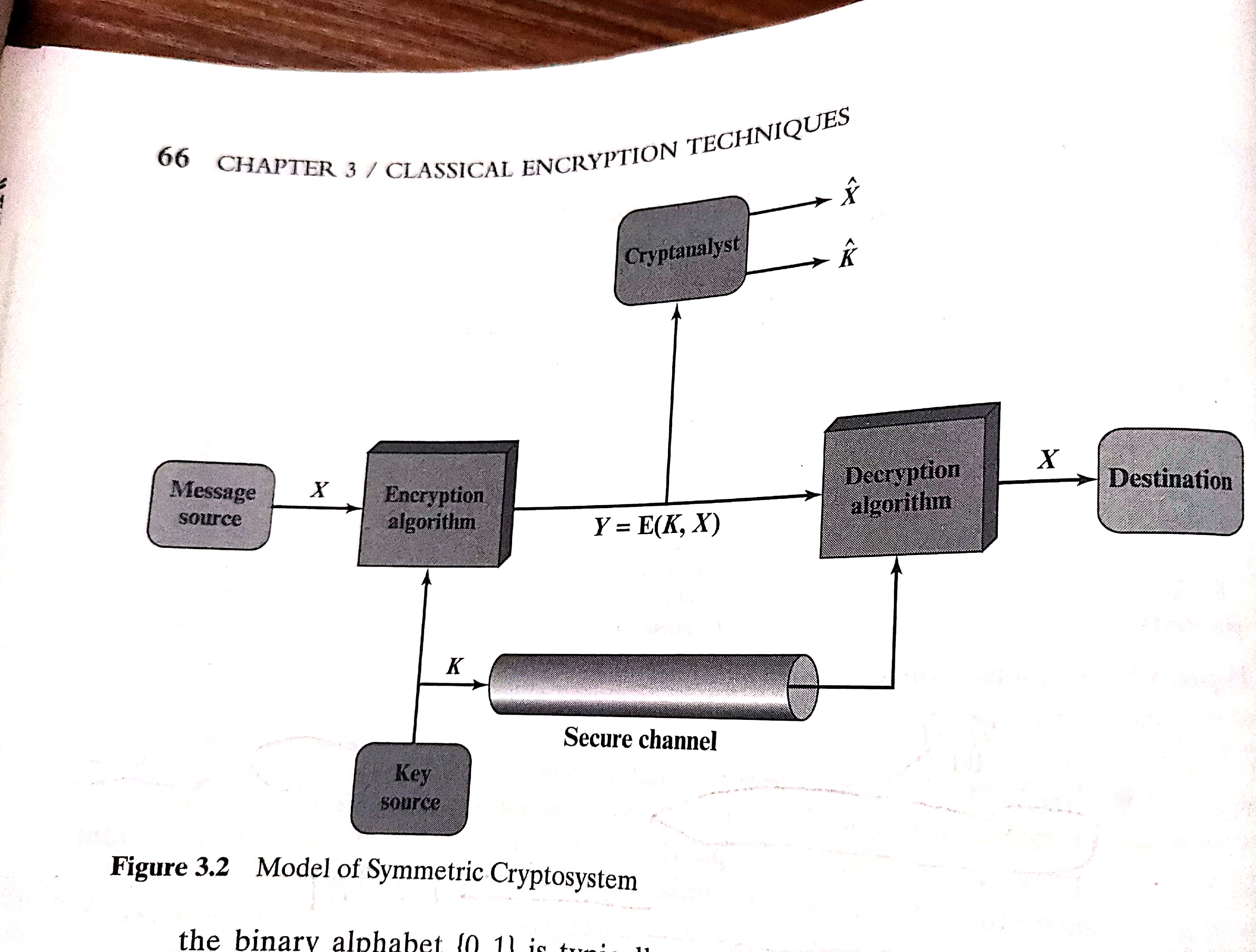
发送方产生明文消息X=,X的M个元素是某个字母表上的字母,传统上,字母表由26个大写字母组成,现在最常用的是二进制字母表{0,1}。加密时,先声成一个形如K=的密钥,如果密钥是由信息的发送方产生的,那么密钥需要通过某些安全的渠道发送到接收方,另一种方法是由可信赖的第三方生成密钥再安全地分发给发送方和接收方。
前面提到,加密算法根据输入信息X和密钥K生成密文Y=,用数学公式可表示为
表示密文Y是明文X的函数,什么样的函数?由密钥K决定。
解密的过程可表示为
1.3 Ctyptography
google了一下,Ctyptography的翻译是密码学,而cryptology的翻译也是密码学,在书里有:
The areas of cryptography and cryptanalysis together are call crtptology
cryptanalysis是密码分析学,看了网上的一些翻译,Ctyptography译为密码编码学好像更好理解一点,这样密码编码学和密码分析学就统称为密码学。
Cryptography systems(密码编码学系统)有三个独立特征:
- The type of operations used for transforming plaintext to ciphertext 就是说是一种把明文转换为密文的运算,所以的加密算法都基于两个原理,代替(substitution)和置换(transposition),代替是将明文中的每个元素(这个元素可以是位(bit),字母(letter)等)映射成(mapped into)另一个元素。置换是将明文中的元素重新排列(rearrange)。运算的基本要求是不允许有信息丢失,也就是说所有的运算是可逆,通过密文和密钥可以解密出明文,并与原来加密前的明文完全一致。
- The number of keys used 使用的密钥数 如果发送方和接收方使用相同的密钥,这种密码就称为对称密码(Symmetric),又称单钥密码,传统密码。如果发收双方使用不同的密钥,这种密码就称为非对称密码(asymmetric),双钥或公钥密码。
- The way in which thee plaintext is processed 处理明文的方式 分组密码(block cipher)每次处理输入的一组元素,相应地输出一组元素。流密码(stream cipher)则是连续地处理输入元素,每次输出一个元素。
1.4 Cryptanalysis and Brute-Force Attack
通常,攻击密码系统的典型目标是得到加密所使用的密钥,而不是仅仅恢复出单个密文对应的明文,攻击传统的密码系统有两种通用的方法
- Crytanalysis 密码分析学: 密码分析学攻击根据于算法的性质,明文的一般特征或某些明密文对,企图利用算法的特征推导出特定的明文和使用的密钥。
- Brute-force attack 穷举攻击 攻击者对一条密文尝试所有可能的密钥,直到把它转换为可读的有意义的明文才算成功。平均而言,获得成功至少要尝试所有密钥的一半。
如果密钥被推导出来了,那么影响是灾难性的(catastrophic),意味着过去的和未来的所有使用该密钥加密的明文都将被推导出来,完全失去了加密的功能。
基于密码分析者知道信息的多少,表3.1概括了密码攻击的几种类型。
其中唯密文攻击(Ciphertext Only)难度最大,我们通常假设攻击者知道加密算法。最简单暴力的方法就是尝试遍所有密钥可能的穷举攻击,但是如果密钥空间非常大,这种方法就不切实际(impractic),我们知道平均而言,获得成功至少要尝试所有密钥的一半。
因此,攻击者必须对密文本身分析,使用各种统计的方法。使用这种统计的方法,攻击者通常也需要对隐含的明文类型有所了解,是英文文本?可执行EXE文件?还是其他具有特定特征的文件。我的理解是,要根据对明文和密文的分析,大量排除掉那些不可能使用的密钥,减小密钥空间,当密钥空间小到一定程序时(也可以说我们已经分析到极限了,无法再通过分析的方法排除密钥),再用穷举攻击去得到有意义的明文。
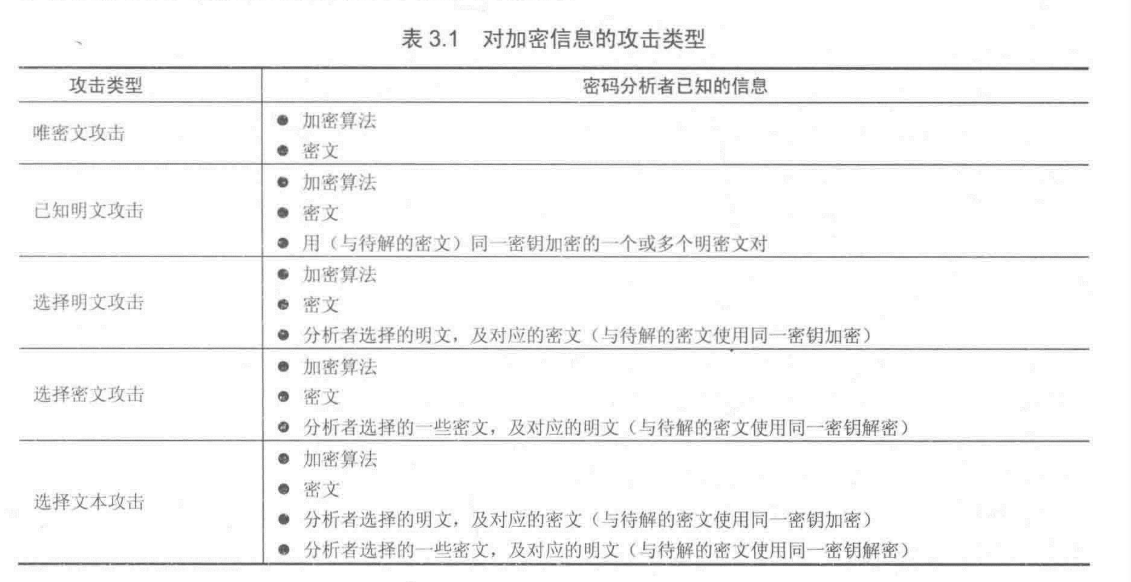
如图表3-1
**唯密文攻击(Ciphertext Only)**是最容易防范的,因为攻击者拥有的信息量最少。
与**已知明文攻击(Known Plaintext)**紧密相关的是可能词攻击(Probable-word attack)。如果攻击者处理的是一般的无固定格式的信息,那么他对信息的内容是一无所知的。但他如果处理的是一些特定的信息,比如特定的文件,一般这些文件的某些位置(比如说文件头部)是固定不变的,所以攻击者可能利用这些固定不变的字段。
如果攻击者能够通过某种方式获得信源系统,可以在发送方发送的信息中插入一段由他自己选择的信息,那么选择明文攻击(Chosen Plaintext)就有可能实现,攻击者当然会选择插入那些最有可能恢复出密钥的数据。
只有相对较弱的算法才抵挡不住唯密文攻击,一般地,加密算法起码要能经受得住已知明文攻击才行。
unconditionally secure 无条件安全 :如果一个密码体制满足条件,那就是:无论有多少可使用的密文,都不足以唯一地确定密文所对应的明文,则称该加密体制是无条件安全的。除了一次一密(one-time pad)之外,所有的加密算法都不是无条件安全的。
但是,尽管很难达到无条件安全,在挑选加密算法时,我们要尽量满足以下两个条件的算法:
- 破译密码的代价超出了密文信息的价值
- 破译密码的时间超出密文信息的有效生命期
满足以上两条标准的任意一条,则称为是计算上安全的(Computationally secure)。
需要提到的是,对称密码的所有分析方法都利用了这样的一个事实:明文的结构和模式(the traces of structure or pattern)在加密之后仍然保存了下来,并能在密文中找到一些蛛丝马迹。
2 SUBTITUTION TECHNIQUES
所有的加密算法都基于两个原理,代替(substitution)和置换(transposition),代替是将明文中的每个元素(这个元素可以是位(bit),字母(letter)等)映射成(mapped into)另一个元素。
如果把明文看成是二进制序列,那么代替就是用密文位串来代替明文位串。
2.1 Caesar 密码
凯撒密码是最早的代替密码,它的加密算法非常简单,就是简单地对字母表中的每个字母,用它之后的第3个字母来代替。
如:
明文:meet me after the toga party
密文:PHHW PH DIWHV WKH WRJD SDUWB
注意字母表是循环的,即紧随Z后的字母是A,我们列出所有的映射关系定义如下变换:
明文 a b c d e f g h i j k l m n o p q r s t u v w x y z
密文 D E F G H I J K L M N O P Q R S T U V W X Y Z A B C
为了方便列出加密算法的表达式,我们让每个字母等价与一个数值:
| a | b | c | d | e | f | g | h | i | j | k | l | m |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| n | o | p | q | r | s | t | u | v | w | x | y | z |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 |
那么加密算法可以如下表达,对于每个明文字母p,代替称密文字母C
同时,移位量可以是任意的整数k,也就是说可以用它之后的第k个字母表示该字母,这样就得到了一般的Caesar算法:
k的取值范围是1~25
解密算法是
如果判断出给定的密文是凯撒密码,破译算法是容易的,因为密钥k只有25种可能,穷举攻击非常容易实现。
2.2 Monoalphabetic Ciphers
Caesar密码仅仅有25种可能的密钥,是远不够安全的,需要增大密钥空间。我们知道Caesar密码密钥k一旦确定,每一个字母都被加密成其后的第k个字母,但如果通过任意替代,密钥空间将会急剧增大。
- permutation 排列:我们定义排列,有限元素的集合S的排列是S的所有元素的有序排放,且每个元素只出现一次,例如S={a,b,c},则S有6个排列 abc,acb,bac,bca,cab,cba,显然,具有n个元素的集合有n!个排列方式。
前面提到的Caesar
明文 a b c d e f g h i j k l m n o p q r s t u v w x y z
密文 D E F G H I J K L M N O P Q R S T U V W X Y Z A B C
如果每一个字母都可以对应26个字母中的任意一个字母,那么我们就有26!或大于4×中可能的密钥,密钥空间大大增大,似乎可以抵挡穷举攻击了。这种方法就称为单表替代 Monoalphabetic Ciphers
考虑以下的一段密文:

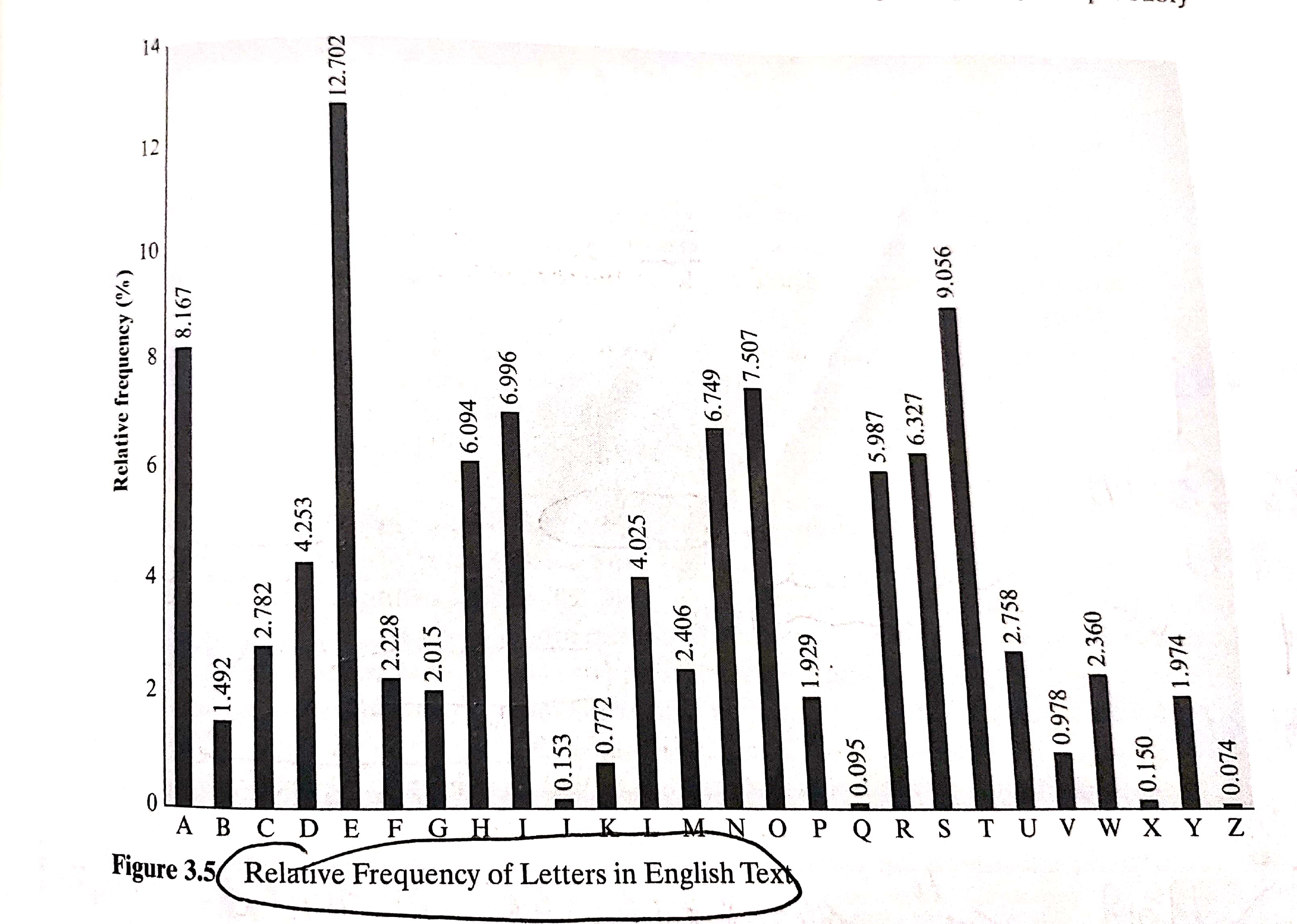
首先我们把字母使用的相对频率统计出来,得到密文中个字母的相对频率(百分比)如下:
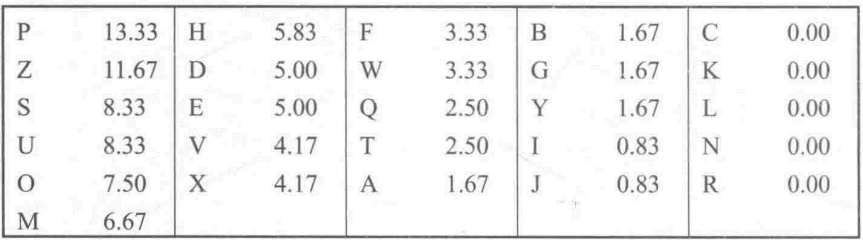
与英文文本中字母的使用频率分布做比较(如下图)
我们在前面提到:
需要提到的是,对称密码的所有分析方法都利用了这样的一个事实:明文的结构和模式(the traces of structure or pattern)在加密之后仍然保存了下来,并能在密文中找到一些蛛丝马迹。
我们所说的明文的结构和模式在加密之后仍然被保存了下来,字母出现的频率就是其中一个特征,明文的字母频率会保存在密文当中。
将明文和密文中的字母的出现频率做比较,我们可以得出初步的结论,密文字母中的P和Z可能相当于明文中的e和t,但是并不能完全确实P对于的是e还是t,Z对应的是e还是t,因为字母频率虽然保存了下来,但并不是完全一致的,是大致接近。原因是英语中各字母的出现频率是基于大量的英文文本统计得到的,而这里一小段密文可能个字母出现的频率会有所差异,当密文的长度足够长时,就会越接近。
S,U,O,M和H的相对频率也比较高,可能与明文中的字母a,h,i,n,o,r,s中某一个对应,以此类推。
此时如何进一步确定对应关系?
统计双字母组合(我们称一个双字母组合为digrams)是比较有效地工具,英语(明文)中最常用的一个字母组合为th,而在我们的密文中,用得最多的双字母组合是ZW,因此我们进一步估计Z对应明文t,W对应明文h,根据先前的假设,可以暂且认为P对应e,所以密文中的ZWP很可能就是the。
进一步观察明文序列,第一行中出现了子序列ZWSZ,根据我们已有的假设,它应该被翻译为th_t,根据我们的英语能力!!!,S很有可能是a,that!。
至此我们得到了以下的结果:
继续以上类似的分析,测试就可以得到完整的明文,加上空格后如下:
单表替代密码改进了凯撒密码密钥空间小的问题,但是仍然容易被攻破,因为密文中仍然保留着原始明文的字母频率等一些统计学特征。解决的对策有对每个字母提供多种代替,一个明文单元变换称不同的密文单元,比如字母e可以替换成16,74,35,21,然后循环或者随机地选取其中一个同音词即可,但仍然存在明文的一个元素只能影响密文中一个元素的缺陷,明文的一些结构和模式还残留在密文中,使得密码分析者得以利用。
有两种主要的减少代替密码明文结构在密文中的残留度,一种是明文中的多个字母(multiple letters)一起加密,另一种是采用多表(multiple cipher alphabets)代替密码,后面会提及。
2.3 Playfair Cipher
The best-known multiple-letter encryption cipher is the Playfair, which treats disgrams in the plaintext as single units and translates these units into ciphertext diagrams.
Playfair 密码是最著名的多字母代替密码,它将明文中的diagrams,也就是双字母组合作为一个单元,并将其转换成密文中的diagram(双字母组合)。
Playfair算法基于一个由密钥词构成的5×5字母矩阵,假设使用的密钥词为monarchy,填充矩阵的方法是首先将密钥词从左至右,从上至下填在矩阵格子中(注意重复字母只填一次),再将剩余的字母按字母表的顺序从左至右,从上至上填在矩阵剩下的格子里,字母I/J暂且当成一个字母。以密钥monarchy为例,填完矩阵如下:
| M | O | N | A | R |
|---|---|---|---|---|
| C | H | Y | B | D |
| E | F | G | I/J | K |
| L | P | Q | S | T |
| U | V | W | X | Z |
对明文的双字母组合按如下的规则加密:
- 如果该字母对的两个相同的,那么在它们之间加一个填充字母,比如x。例如balloon先把它变成ba lx lo on 这样四个字母对。
- 落在矩阵同一行的明文字母对中的字母均由其右边的字母来代替,每行的最右边一个字母就用该行的最左边的第一个字母代替,相当于一个循环,比如AR就变成RM。
- 落在矩阵同一列中的明文字母对中的字母均由其下方的字母来代替,每列中最下面的一个字母由每列的最上面字母代替,比如mu就变成CM。
- 其他的明文的字母对按以下的方式代替,该字母所在的行作为对应密文字母的行,另一字母的列作为对应密文字母所在的列,比如hs变成BP,ea变成IM(或JM)。
Playfair密码相对于简单地单表密码进步在于,26个字母共有676种字母对组合,因此识别出单个字母对要困难得多,同时因为是两个字母加密得到两个字母。单个字母的相对频率特征(在密文中的残留度)在一定程度上减弱了,这样利用频率分析字母对就更困难一些。
虽然在一定程度上减弱了,但是它的密文仍然完好地保留了明文的大部分结构特征(频率特征)。
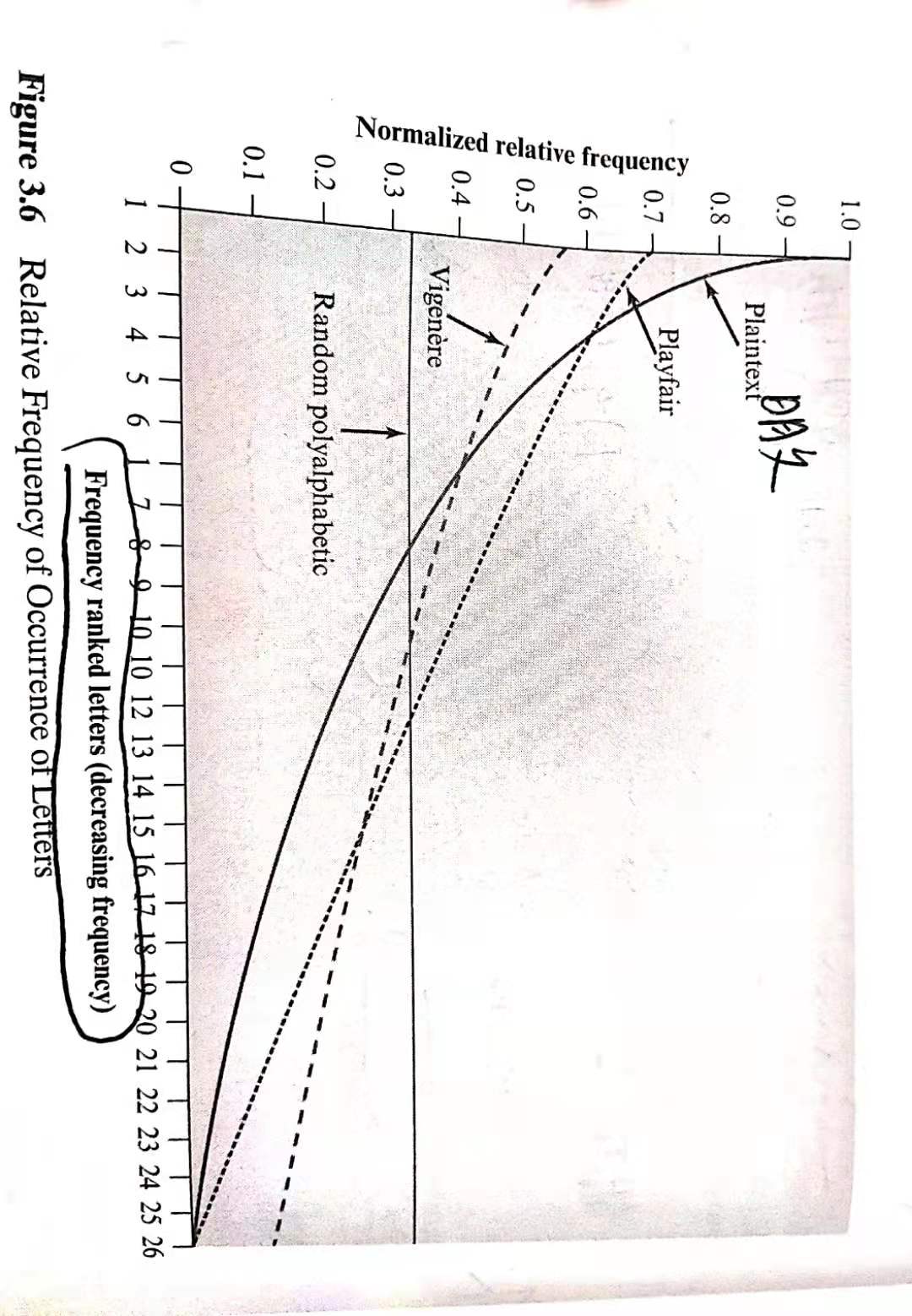
图3.6显示了Playfair密码和其他一些密码加密的有效性。标有"明文"的曲线画出了26个字母的频率分布(不区分大小写),这也是任意单表代替密码的频率分布,因为单表代替密码的方式是一个明文字母对应一个密文字母,所以频率被完整保留了下来。
曲线代表的意思是:对文章中出现的每个字母计数,计数结果除以使用频率最高的字母e的出现次数,设e出现的频率为1,则t大约为9.056/12.702约为0.72。水平轴上的点对应着按使用频率递降的字母。
也表明了使用Playfair密码加密后文本的字母频率分布情况,曲线体现了加密后字母频率分布被隐藏的程度,单表代替密码,有了提高。
可以看到一条水平的线,该线表示,频率分布的信息完全被加密过程隐藏了,唯密文密码分析由字母频率去下手一无所获,因为每个字母出现的相对频率都是一样的。
2.4 Hill Cipher
Hill密码属于多表代替密码(multiletter cipher)。
Hill密码需要一些线代代数的知识。定义方阵M,M有逆矩阵满足M()=()M=I,其中I为单位矩阵。
Hill算法 该加密算法将m个连续地明文字母代替成m个密文字母,这是由m个线性等式决定的,在等式里每一个字母被指定为一个数值,例如m=3,系统可以描述为:
展开有:
或
C和K是长度为3的行向量,分别代表密文和明文,K为3×3的矩阵,代表加密密钥,运算按模26执行。
举书里的例子,明文为“paymoremoney",加密密钥为
明文以三个字母为一组,用向量表示,比如前三个字母用向量表示为(15 2 24),那么(15 0 24) K = (303 303 531) mod 26 =(17 17 11)=RRL,照此方式转换余下字母,可得整段明文对应的密文为RRLMWBKASPDH。
解密则需要矩阵K的逆矩阵,表示为
同Playfair密码相比,Hill密码的优点是完全隐蔽了单字母频率特性,因为Hill密码是m个明文字母影响m个密文字母。如果用的密钥矩阵越大,隐藏的频率信息就越多。
Hill密码能很好地抵挡唯密文攻击,但是它容易被已知明文攻击破解。考虑以下的例子,假设明文"hillcipher"经过一个2×2的Hill密码加密生成HCRZSSXNSP,因此我们知道hi=(7,8)被加密为HC=(7,2),有(7 8)K mod 26 =(7 2) 同理 (11 11)K mod 26 = (17 25);以此类推,由前两个明密文对,可得
弱弱问一句,有没有看官知道逆矩阵怎么用LATEX书写出来…
因此
得到了密钥K,可以由剩下的明密文对去验证。
2.5 Polyalphabetic Ciphers
对简单单表代替的改进方法是在明文消息中采用不同的单表代替,这种方法我们一般称之为多表代替密码。所以这些方法都有以下的共同特征:
- 采用相关的单表代替规则集。
- 密钥决定变换的具体规则。
Vigenere 密码
Vigenere代替规则由26个Caesar密码的代替表组成,其中每一个代替表是对明文字母表移位0~25次后得到的代替单表。每个密码由一个密钥字母来表示。
可以那个如下的方式表述Vigenere密码,假设明文序列为,密钥由序列构成,其中m<n。密码序列,计算如下:
注意对应的密钥字母为,开始新一轮的循环。
所以,加密过程的一般方程为:
与Caesar密码的加密过程的表达式类似,本质上,每一个明文字母根据相应的密钥字母进行着Caesar密码加密。
解密过程也与Caesar密码类似:
加密一条消息需要与消息一样长的密钥。所以通常,密钥是一个密钥词的重复,比如密钥词为deceptive,那么消息"we are discovered save yourself"将被这样加密

用表格来表述,有: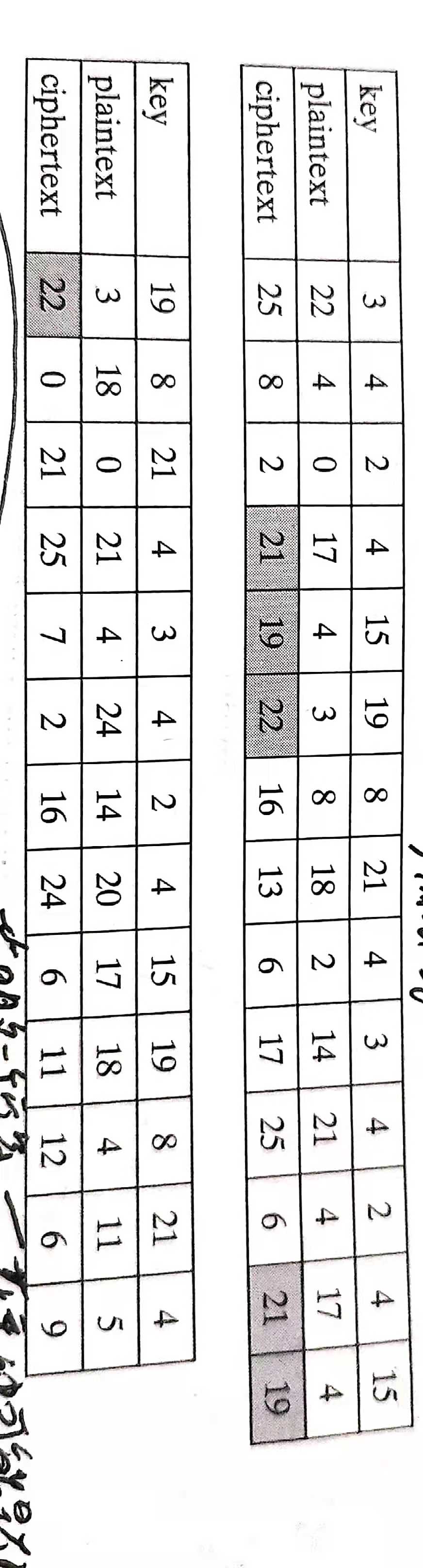
这种密码的强度在于每个明文字母对应着多个密文字母,且每个密文字母使用唯一的密钥字母,因此字母出现的频率信息被屏蔽了。
破译Vigenere密码的关键在于能否判断密钥词的长度。
很关键的一点,如果两个相同的明文序列之间的距离是密钥词长度的整数倍,那么产生的密文序列也是相同的。因为明文序列相同,距离是密钥词长度的整数倍,所以对应的密钥字母相等,这样产生的密文序列也一定相同。
实际上,如果密钥长度是m,那么密码实际上包含了m个单表代替。以DECEPTIVE作为密钥词,那么处在位置1,10,19,…的字母的加密实际上是凯撒密码(单表加密),因为他们都加上D,mod 26。因此,如果我们得到了密钥的长度m,我们可以将密文拆成多个凯撒密码加密(单表代替),然后利用单表代替加密没有消除的频率特征分布进行攻击,破译密码。
Vernam CIPHER
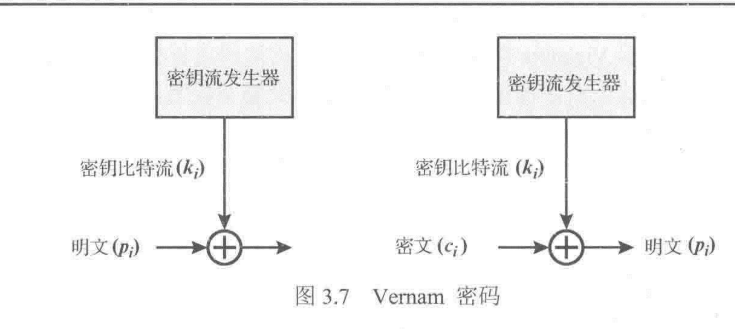
Vernam密码其运算基于二进制数据而非字母,该加密过程可以简明的描述为:
其中
是明文第i个二进制位,
是密钥的第i个二进制位,
是密文的第i个二进制位,使用的是异或运算。
根据异或运算的性质,解密过程为:
这种加密技术的本质在于构造密钥的方式。
Vernam也是一种流密码(Stream Ciphers)。流密码的定义简单来说将明文看成字符串或比特流,并逐字符或逐比特进行加密。
A stream cipher is one that encrypts a digital stream ont bit or one byte at a time。
2.6 One-Time pad
One-Time pad为一次一密。是对Vernam密码的改进方案,从而达到了最完善的安全性。
One-Time pad使用与消息(明文)一样长且无重复的随机密钥流来加密消息,另外,密钥只对一个消息进行加解密,之后就丢弃不用了。因此,每一条新消息都需要一个与其等长的新密钥流,这就是著名的一次一密。它是不可攻破的(unbreakable)。
如果密码分析者得到了密文,假设出了两个密钥,破译出明文,但他没有理由认为哪一个明文是正确的。因此这种密码是不可破的。
一次一密的安全性完全取决于密钥的随机性。如果构成密钥的字符流是真正随机地,那么构成密文的字符流也是真正随机的,因此分析者没有任何攻击密文的模式和规律可用。
理论上,One-Time pad提供了完美的安全性,但在实际中,存在两个基本的难点
- 产生大规模随机密钥是有困难的。
- 密钥的分配和保护。每一条发送的消息,都需要提供给发送方和接收方等长的密钥,存在着庞大的密钥分配问题。
一次一密是唯一的具有完美保密(perfect secrecy)的密码机制。
任何满足perfect secrecy的加密系统都需要满足两个前提:
- 密钥空间足够大,至少等于明文空间
- 一个密钥只能用于一次加密
但实际上perfect secrecy的加密系统的不切实际的(impractical),原因就在于以上说的两个难点。
在理想状况下,除非是获得了密钥比特流,否则这个密码是不可破的,然而密钥流也必须以某种独立,安全的信道提供给发送方和接收方双方,但如果待传递的密钥流很长,造成的"通信流量"很大,这就成为了一个障碍,相应的出于实用的原因,密钥流可以以算法程序(这里称为比特流生成算法,算法以密钥K为input,获得密钥比特流作为output)的方式实现,从而双方都可以生成密钥比特流,在这种方法中,两个用户只需要共享生成密钥,就可以各自生成密钥流。
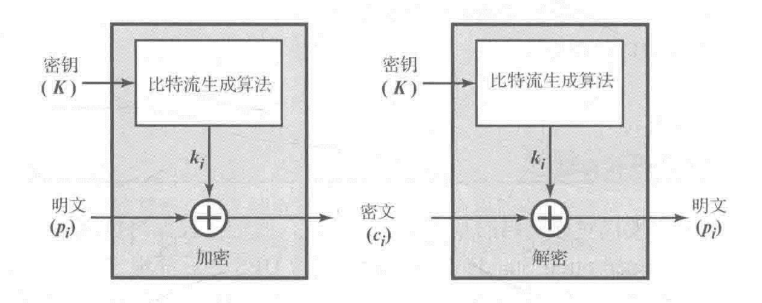
3 TRANSPOSITION TECHNIQUES
到目前为止,前面我们所讨论的都是将明文字母代替为密文字母,与之非常不同的一种加密方法是对明文进行置换 Transposition,这种密码称为置换密码。
最简单的例子是栅栏(fence)技术,按照对角线的顺序写出明文,而按行的顺序读出作为密文。例如,假设用密钥为2的栅栏技术加密信息“meet me after the toga party" 可写为
1 | m.e.m.a.t.r.h.t.g.p.r.y |
根据行读出作为密文,加密后的信息为MEMATRHTGPRYETEFETEOAAT
再比如使用密钥为8的V型栅栏密码加密明文“Don’t deny something easily, maybe you’re just in a bad mood today”(不要轻易否认一切事情,你可能今天只是心情不好!)
1 | D............. e.............m.............u.............o............. |
按行读出密文位:DEMUOOMTAJSMONOHYY T’D’SILBE D T NIERIAT YGS 'NBO!DN AYU DYEEOAA
因为形状像V,也称位V型栅栏密码
一个更复杂的方案是把消息一行一行地写成矩形块,然后按列读出,把列的次序打乱,列的次序就是算法的密钥。例如:

明文为"attackpostponeduntiltwoamxyz",按行写入矩阵,然后按密钥给出的各列次序,依次读出各列作为密文,最终密文为TTNAAPTMTDUOAODWCDIXKNLYPETZ
单纯的置换密码因为有着与原始明文相同的字母频率特征而容易被识别,因为置换只是将位置打乱,并没有将各元素改变。
多次置换密码使得消息更难被重构起来,我们可以用前面得到的密文TTNAAPTMTDUOAODWCDIXKNLYPETZ作为明文,做再一次的置换,得到新的密文,如图:

这样操作后,分析者攻击它要困难得多了~
终于写完了(这玩意居然写了我一天?!)
仅仅是初学者的学习笔记,很多东西还没有学到而且对新学的东西认识也还很浅,如有错误,欢迎指正!!!!
参考资料 《密码编码学与网络安全》第八版